
Chemistry-informed Transformers for Reaction Prediction and Retrosynthesis
Published:
The transformer architecture has remarkably improved the accuracy of sequence modeling tasks (eg. language translation) but could they be used to model chemical reactions? Do chemical reactions have some similarity with natural language that allows for the use of powerful transformer-inspired architectures? How would the molecules be represented in such frameworks so that appropriate chemical structural information is captured? Are there other potential transformer-like architectures that could handle chemical representations better compared to the vanilla transformer model?
To use the transformer architecture, two requirements have to be satisfied -- first, chemicals participating in a reaction should be represented using text-based representations (akin to words in a sentence), and second, the reaction modeling problem needs to be formulated as a 'language translation' task. Thus, based on this analogy, participating chemicals are 'words' and left-hand-side of reactions are 'sentences' (in reactants language) that need to be 'translated' to the right-hand-side 'sentences' (in products language). Our series of works using this analogy (paper 4, paper 3, paper 2, paper 1) first addressed the issue of using an appropriate chemical grammar-based representation followed by proposing a novel tree-transformer architecture that could perform the translation using molecular trees as input in a chemistry-aware manner.
The machine translation framework for reaction modeling is shown in the Figure 1 below. The forward translation (from reactants to products) is used to predict chemical reaction outcomes, and the inverse translation (from product to reactants) is used to solve the retrosynthesis problem. The first important question is how to represent the input and output molecules?

Can we do better than the SMILES representation?
The most commonly used representation is the SMILES representation where molecules are represented using a linear text-based notation. For instance, for say cyclopropane, the SMILES representation is C1CC1. While the SMILES representation is vastly used, it contains little explicitly encoded chemical structural information. On the other hand, the grammar parse tree shown in Figure 2 contains additional relevant information. For instance, it contains information such as the number of aromatic carbon atoms, the presence of a ring-structure, the alternating double bonds in the ring, the presence of an aliphatic oxygen atom, and finally the active hydrogen atom attached to the oxygen atom. Moreover, this information is represented in a hierarchical manner, with the broadest class of rules at the top and increasingly more specific ones toward the bottom of the parse-tree. We thus proposed a SMILES grammar-based representation based on these parse trees for molecules. We showed that these representations are better from a model performance as well as information theoretic standpoint, since the conditional entropy (or uncertainty) associated with it is the lowest, thus aiding data-driven approaches in modeling and discovering patterns efficiently.
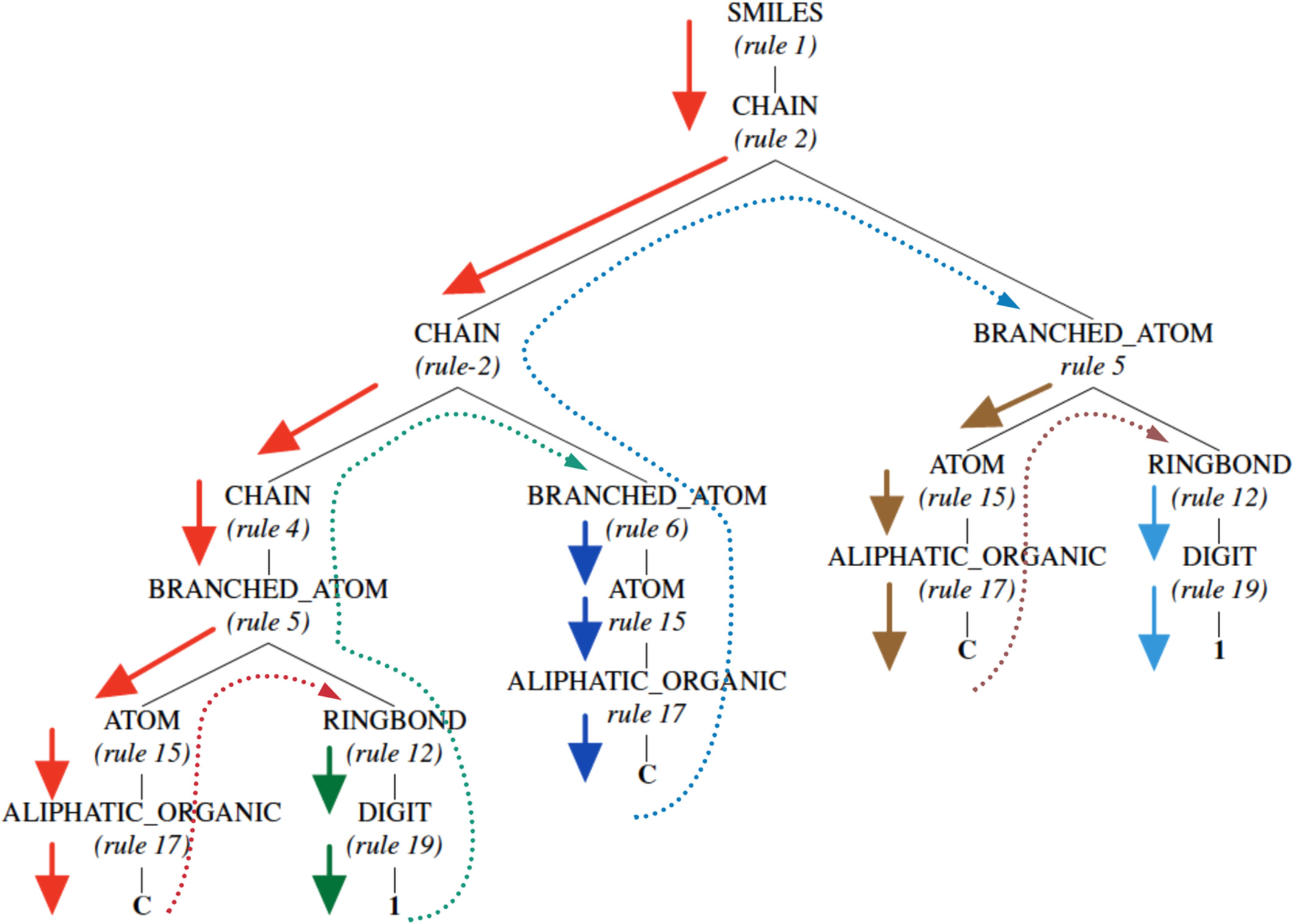
Can we do better than the vanilla transformer architecture?
The second important question to answer is can the transformer model be adapted to better handle hierarchical chemistry-informed molecular representations? This would allow for the entire grammar (instead of linearized SMILES grammar tree) to be input to the transformer architecture and preserve the structural hierarchy that is inherently encoded. To this end, we modified the transformer architecture and proposed a novel tree transformer architecture for modeling retrosynthesis problems as shown in Figure 3 below.
![]()
The tree transformer model comprises two major changes -- first, tree positional encoding that encodes positions in a tree capturing parent/child/sibling relationships representing the underlying hierarchy, and second, tree convolution operations that performs convolutions operations around nodes in the tree to capture contextual information. The tree convolution operations allow for structural information to be encoded in the latent space utilizing structural information to the fullest extent.
Results
The results on the forward prediction and the retrosynthesis prediction are shown below. Note that we only demonstrate the tree transformer approach on the retrosynthesis model but it could be easily applied for the forward prediction model just by reversing the direction of translation and should result in improved performance.
| Model | Top 1 | Top 2 | Top 3 | Top 5 | Top 10 |
|---|---|---|---|---|---|
| forward (grammar linearized) | 80.1 | 86.3 | 88.7 | ||
| retrosynthesis (grammar tree, with class) | 51.0 | 64.3 | 70.0 | 74.6 | 79.1 |
| retrosynthesis (grammar tree, no class) | 41.6 | 54.0 | 60.4 | 67.6 | 73.1 |
| Model | Top 1 | Top 2 | Top 3 | Top 5 | Top 10 |
|---|---|---|---|---|---|
| forward (grammar linearized) | 1.0 | ||||
| retrosynthesis (grammar tree, with class) | 1.5 | 2.7 | 4.0 | 6.0 | 9.8 |
| retrosynthesis (grammar tree, no class) | 1.3 | 2.0 | 2.6 | 3.8 | 6.0 |
Further results, detailed analyses, and additional chemistry-based statistics are presented in our published articles -- retrosynthesis tree transformer, forward prediction, information-theoretic analysis, and review article.
